Thursday, October 6, 2011
Monday, August 8, 2011
Friday, July 22, 2011
Multisample Soft Shadows
Recently, I was thinking which way should further develop the implementation of soft shadows. I can see clearly now that the approximation of extended light source to a single point is unacceptable. Of course, we can restrict light source area to a smaller size: in this case errors caused by approximation are negligible. However, this is one of the main advantages of the algorithm, and I don't want to drop it. To get a better understanding of errors caused by approximation, I added to the implementation the possibility to work with multiple samples on light source: silhouette, shadow volume and penumbra are considered for each sample. Here are some images:





It's clearly seen that if extended light source is approximated by single sample, penumbra become incorrect. Several samples instead of one slow down the algorithm, but one can notice that umbra and penumbra now separated from each other to some extent: the shadow becomes more plausible.
The authors of the original penumbra wedges algorithm do not set themselves to solve the problem of approximation. To solve it, it's needed to change the approach. For example, the algorithm was originally based on the construction of the shadow volume from the center of the light source, followed by lighting compensation in penumbra around the edges of hard shadow. I think it would be better to go this way: consider coverage in penumbra without the sign (it depends on whether we're inside the hard shadow or outside it), and instead of extrusion of classic shadow volume, determine the umbra region and shade it to black - there's no any lighting contribution. Thus here are two logical parts: umbra, where there's no illumination and penumbra, where the pixel shader computes it analytically.
It's unclear now how to calculate umbra for an extended light source, but definitely nothing impossible.

1x

4x

1x

4x

Penumbra area (debug view)
It's clearly seen that if extended light source is approximated by single sample, penumbra become incorrect. Several samples instead of one slow down the algorithm, but one can notice that umbra and penumbra now separated from each other to some extent: the shadow becomes more plausible.
The authors of the original penumbra wedges algorithm do not set themselves to solve the problem of approximation. To solve it, it's needed to change the approach. For example, the algorithm was originally based on the construction of the shadow volume from the center of the light source, followed by lighting compensation in penumbra around the edges of hard shadow. I think it would be better to go this way: consider coverage in penumbra without the sign (it depends on whether we're inside the hard shadow or outside it), and instead of extrusion of classic shadow volume, determine the umbra region and shade it to black - there's no any lighting contribution. Thus here are two logical parts: umbra, where there's no illumination and penumbra, where the pixel shader computes it analytically.
It's unclear now how to calculate umbra for an extended light source, but definitely nothing impossible.
Thursday, July 7, 2011
GL_EXTENSIONS
A few days ago I tried to play Quake II (do not laugh - it's the game of all time) on my laptop with Windows 7 and couldn't - the game didn't work. Compatibility mode doesn't give any results.
I found q2source-3.21 archive, builded debug configuration, reassign the paths and ran it. Crash. I started debugging, came to ref_gl initialization and saw that the engine stumbles upon common error - buffer overflow, when trying to output GL_EXTENSIONS string.
The fact is that the constant MAXPRINTMSG (function VID_Printf) equals to 4096, which is not enough for such string in our time - it has grown too much over the years. If you increase the constant by two - the problem goes away. C - unsafe language :)
This problem was solved in OpenGL 3.x, where you don't get the entire list of extensions in one string, but the name of each extension by its index (glGetStringi). SGI had to do that in the initial design of the API, but no one then thought that the extension mechanism will turn into a loony bin, eh?
I found q2source-3.21 archive, builded debug configuration, reassign the paths and ran it. Crash. I started debugging, came to ref_gl initialization and saw that the engine stumbles upon common error - buffer overflow, when trying to output GL_EXTENSIONS string.
The fact is that the constant MAXPRINTMSG (function VID_Printf) equals to 4096, which is not enough for such string in our time - it has grown too much over the years. If you increase the constant by two - the problem goes away. C - unsafe language :)
This problem was solved in OpenGL 3.x, where you don't get the entire list of extensions in one string, but the name of each extension by its index (glGetStringi). SGI had to do that in the initial design of the API, but no one then thought that the extension mechanism will turn into a loony bin, eh?
Monday, June 13, 2011
Multipoint Silhouette Determination
I have developed multipoint silhouette determination on CPU with volume extrusion in the geometry shader. The reason why CPU is used is that geometry shader uses adjacency faces for silhouette determination, but for efficient implementation we need to iterate over mesh edges and see the orientation of their left and right adjacent faces that geometry shader can't do. The problem can be solved using compute shader with arbitrary data layout, but my laptop GPU is capable only of SM 4.1.


Of course with each additional light sample the shadow volume overdraw is significantly increased.


Of course with each additional light sample the shadow volume overdraw is significantly increased.
Friday, June 3, 2011
Rectangular Light Source
The last few days I was in the debugging of penumbra shaders for rectangular light source. All my previous soft shadows implementations supported spherical light sources only and with rectagular light there was an incorrect shading. In the end I wrote a shader algorithm in C++ and debugged a few test cases. It turned out that the correct solution requires inverting 3x3 matrix directly in the pixel shader, which in the original implementation of the algorithm I haven't seen. Software implementation helped to understand all the subtleties of the algorithm (that's almost impossible with HLSL and GPU-oriented tools).



Due to low-poly geometry and rectangular shape of light source penumbra looks a bit angular. But the major problem is "single point silhouette approximation", I've written about it here (sorry, in russian). Because of this simplification the shadow looks like overshadowed, because not all potential silhouette edges contributed to penumbra. I don't like how the shadow looks, so I plan to implement more sophisticated silhouette edges determination.



Due to low-poly geometry and rectangular shape of light source penumbra looks a bit angular. But the major problem is "single point silhouette approximation", I've written about it here (sorry, in russian). Because of this simplification the shadow looks like overshadowed, because not all potential silhouette edges contributed to penumbra. I don't like how the shadow looks, so I plan to implement more sophisticated silhouette edges determination.
Tuesday, May 31, 2011

Friday, May 27, 2011
Second Anniversary
Due to the second anniversary of my russian blog, I have prepared some screenshots:




The code is still far from perfect, images have a lot of artifacts (fireflies), there are numerous thing that I want to develop, debug and polish. But for the first time soft shadows are implemented using the power of Direct3D 11.




The code is still far from perfect, images have a lot of artifacts (fireflies), there are numerous thing that I want to develop, debug and polish. But for the first time soft shadows are implemented using the power of Direct3D 11.
Wednesday, May 18, 2011
Packed Stream Output
There is some inconsistency in D3D 10/11 hardware - input layout stage can fetch data with different formats, but stream output can write to target buffers only 32-bit values (you can find a note about this in the Direct3D 10 programming guide, in the very end of Getting Started with the Stream-Output Stage section). Nevertheless, usually float precision is too excessive for local models, and it is desired to output data with half precision.
SM 5.0 has two functions for float-to-half conversion and vice versa: f32tof16() and f16tof32(). There is a dedicated silicon in DX11-hardware for these operations, so they are first-class API citizens. Also these functions are available under SM 4.0 profile - in that case they are emulated by a series of bit shifts, integer multiplications etc. I stumbled upon implementation of these functions in the OpenGL RedBook: Floating-Point Formats Used in OpenGL (probably, the algorithm implemented according to the IEEE 754-2008 specification for half precision floating-point format). Some time ago I wrote my own conversion functions, that work through lookup table, but with advent of SM 5.0 they are can be thrown away :)
I came up with idea that with SM 5.0 we can pack two floats into one, and stream out from geometry shader (and fetch later with input assembler) 2x less data than normally. Besides, important declaration [maxvertexcount] can be reduced: for example, if previously GS was outputing two vertices, now it will output only one. The main idea is: SO outputs two halves packed into single float, and IA interprets the vertex buffer as R16G16B16A16_FLOAT, so we can easily read each packed vertex.
Here is the code that packs two three-component vectors into one four-component: pck. The fourth component is required because R16G16B16A16_FLOAT format has four components (6-byte three-component formats was never supported by hardware), but we can ignore it when reading from vertex buffer or packing as well.
It is easy to pack until we stream out even number of vertives: 2, 4 and so on. But what if we need to output three vertices (say, triangle)? We can pack first two vertices into float4, third vertex - into .xy components of second float4 and left .zw uninitialized. But with subsequent fetch we will read three half4, and the fourth will belong to the next primitive - an error! And we can't define a stride between primitives in the buffer - no one wants to leave a gaps in the memory.
The solution is simple. Before we were packing four vertices into two, for instance, now we would have to pack three vertices into one:
IA will interpret vertex buffer as series of half4 - thats all.
SM 5.0 has two functions for float-to-half conversion and vice versa: f32tof16() and f16tof32(). There is a dedicated silicon in DX11-hardware for these operations, so they are first-class API citizens. Also these functions are available under SM 4.0 profile - in that case they are emulated by a series of bit shifts, integer multiplications etc. I stumbled upon implementation of these functions in the OpenGL RedBook: Floating-Point Formats Used in OpenGL (probably, the algorithm implemented according to the IEEE 754-2008 specification for half precision floating-point format). Some time ago I wrote my own conversion functions, that work through lookup table, but with advent of SM 5.0 they are can be thrown away :)
I came up with idea that with SM 5.0 we can pack two floats into one, and stream out from geometry shader (and fetch later with input assembler) 2x less data than normally. Besides, important declaration [maxvertexcount] can be reduced: for example, if previously GS was outputing two vertices, now it will output only one. The main idea is: SO outputs two halves packed into single float, and IA interprets the vertex buffer as R16G16B16A16_FLOAT, so we can easily read each packed vertex.
Here is the code that packs two three-component vectors into one four-component: pck. The fourth component is required because R16G16B16A16_FLOAT format has four components (6-byte three-component formats was never supported by hardware), but we can ignore it when reading from vertex buffer or packing as well.
It is easy to pack until we stream out even number of vertives: 2, 4 and so on. But what if we need to output three vertices (say, triangle)? We can pack first two vertices into float4, third vertex - into .xy components of second float4 and left .zw uninitialized. But with subsequent fetch we will read three half4, and the fourth will belong to the next primitive - an error! And we can't define a stride between primitives in the buffer - no one wants to leave a gaps in the memory.
The solution is simple. Before we were packing four vertices into two, for instance, now we would have to pack three vertices into one:
struct gs_out
{
vec4 pos1_pos2 : Data0;
vec2 pos3 : Data1;
};
[maxvertexcount(1)]
gs_main(..., PointStream< gs_out > stream)
{
...
}
IA will interpret vertex buffer as series of half4 - thats all.
Friday, May 6, 2011
T-junction Elimination
I encontered some artifacts when rendering stencil shadows from md2 meshes. As it turned out, even a low-poly models from Quake II are not without bugs (I was hoping that everything will be fine). Apparently this is due to the fact that initially they were not intended for casting the shadows, though one may notice, that they respected the rules of two-manifold geometry.
In general, the converter had to be refined so that it can determine non-adjacent clusters of triangles, eliminate T-junctions, do a search based on coincident vertices, etc. In the end I managed to get around of minor bugs and removed invalid triangles from mesh adjacency.


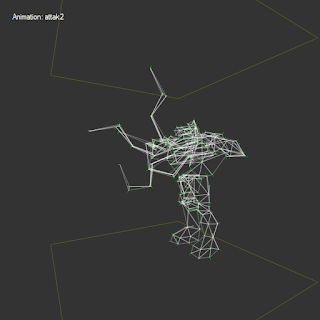
In general, a number of models does not contain any errors. But for example, the "bitch" lost en entire shoulder (as it turned out, there is some kind of porridge made of triangles).
In general, the converter had to be refined so that it can determine non-adjacent clusters of triangles, eliminate T-junctions, do a search based on coincident vertices, etc. In the end I managed to get around of minor bugs and removed invalid triangles from mesh adjacency.



In general, a number of models does not contain any errors. But for example, the "bitch" lost en entire shoulder (as it turned out, there is some kind of porridge made of triangles).
Subscribe to:
Comments (Atom)